集智俱樂部
導語
圖神經網絡(GNN)架構在2018年取得了很多突破,但對其效果的評價准存在一定爭議。而arxiv.org上最近的一項研究,揭露了現有圖網絡效果評價標準的缺陷,並提出了更為合理、全面的評價方案。
圖(graph)中的半監督節點分類(Semi-supervised node classification)是圖挖掘的一個基本問題,最近提出的圖神經網絡(GNN)已經在這個任務上取得了無可比擬的成果。由於其巨大的成功,GNN引起了很多關注,並且已經提出了許多新穎的架構。比如,今年6月DeepMind提出能夠因果推理的圖網絡,並提供了開源的圖網絡庫。
但是,近日發表在arxiv.org的一個研究表明:現有的GNN模型評估策略存在嚴重缺陷,比如:使用相同數據集的相同訓練/驗證/測試分割,或者在訓練過程中進行重大更改(例如,早期停止策略(early stoping criteria)),這樣對不同體系架構的比較是不公平的。
論文題目:
Pitfalls of Graph Neural Network Evaluation
論文地址:
因此研究者對四個出色的GNN模型進行了全面的實證評估,並且發現對數據採用不同的分割方式會導致模型的排名顯著不同。更重要的是,研究結果表明,如果超參數(hyperparameters)和訓練程序適用於所有模型,那麼簡單的GNN架構能夠勝過更複雜的架構。
為什麼性能無法評估?
圖上的半監督節點分類是圖挖掘中的經典問題,其應用範圍從電子商務到計算生物學。最近提出的圖神經網絡架構在這項任務上取得了前所未有的成果,並顯著提升了現有技術水平。儘管取得了巨大的成功,但由於實證評估過程的某些問題,我們無法準確判斷正在取得的進展。部分原因是現在的評估實驗大多是複製早期的標準實驗設置。
首先,許多提出的模型都採用了Yang等人的三個數據集(CORA,CiteSeer和PubMed),並且在相同的訓練/驗證/測試分割上進行的,這樣的實驗設置其實最利於過擬合,因為這些模型最能克服數據集的分割,找到具有最佳泛化屬性的模型。
其次,在評估新模型的性能時,人們經常使用與基準的過程完全不同的訓練過程,這使得難以確定改進的性能是來自(a)新模型的優越架構,還是(b)更好地調整了訓練過程和/或超參數配置,這對新模型的評估是不利的。
在該研究中,研究者解決了這些問題,並對四個主要GNN架構(GCN、MoNet、GraphSage、GAT)在直推式半監督節點分類任務(transductive semi-supervised node classification task)中的表現進行了全面的實驗評估。
在該研究的評估中,主要關注了兩個方面:對所有模型使用標準化訓練過程和超參數選擇。在這種情況下,性能差異可以歸因於模型架構的差異,而不是其他因素。其次,該研究在4個著名的引文網絡數據集上進行實驗,以及另外引入了4個新的數據集。對於每個數據集,使用100次隨機訓練/驗證/測試分割,並且為每個分割執行了20次隨機初始化。這樣的設置能更準確地評估不同模型的泛化性能,而不是僅僅在一個固定測試集上表現得很好。
對比各種模型
該研究定義的圖上的直推式半監督節點分類的問題,和Yang等人的定義相同。 在該研究中比較了以下四種流行的圖神經網絡架構。
(1)圖卷積神經網絡(GCN)是通過對譜圖卷積(spectral graph convolutions)進行線性近似的早期模型之一。
(2)混合模型網絡(MoNet)概括了GCN架構,並允許學習合適的卷積濾波器。
(3)Graph Attention Network(GAT)的創建者提出了一種注意機制,允許在整合期間對鄰域中的節點進行不同的加權。
(4)GraphSAGE專注于歸納節點分類,但也可以應用於直推式學習。 該研究從原始論文中考慮了GraphSAGE模型的3種變體,表示為GS-mean,GS-meanpool和GS-maxpool。
所有上述模型的原始論文和實施都考慮了不同的訓練過程,包括不同的早期停止策略、學習率衰減、全批次與小批量訓練。這種多樣化的實驗設置使得:很難憑經驗確定改進性能背後的驅動因素。因此,在該研究的實驗中,研究者對所有模型使用標準化的訓練和超參數調整程序,以更公平地比較。
此外,該研究還考慮了四種基準模型。 Logistic回歸(LogReg)和多層感知器(MLP)是基於屬性的模型,不考慮圖結構。另一方面,標籤傳播(LabelProp)和歸一化拉普拉斯標籤傳播(LabelProp NL)僅考慮圖形結構並忽略節點屬性。
如何平衡地比較?
實驗中的數據集
該研究使用了四個眾所周知的引用網絡數據集:PubMed、CiteSeer和CORA以及CORA的擴展版本(CORA-Full)。另外還為節點分類任務引入了四個新數據集:Coauthor CS,Coauthor Physics,Amazon Computers和Amazon Photo。對於所有數據集,都構建成了無向圖,僅考慮最大的連通部分。
模型設置
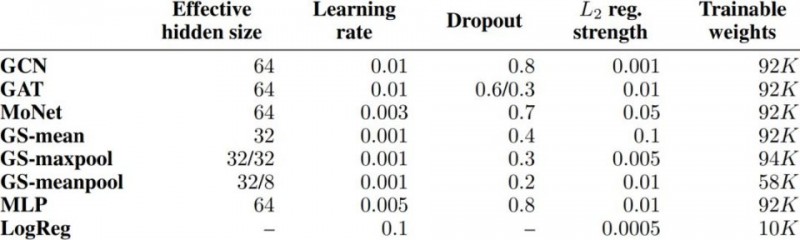
該研究保留了原始論文中的模型體系結構,包括層的類型和順序、激活函數的選擇、dropout的放置以及應用L2正則化的選擇。還將GAT的head數量固定為8,將MoNet的高斯內核數量固定為2,如各自的論文所述。 所有模型都有2層(輸入特徵→隱藏層→輸出層)。
訓練過程
為了更平衡地比較,該研究對所有模型使用相同的訓練過程。也就是說,使用相同的優化器(默認參數的Adam),相同的初始化(根據Glorot和Bengio,初始化權重,偏置初始化為零),沒有學習率衰減,相同的最大訓練疊代次數、早期停止標準、patience和驗證頻率(顯示步驟)。實驗中同時優化所有模型參數(GAT的注意力權重,MoNet的內核參數,所有模型的權重矩陣)。在所有情況下,都使用全批量訓練(使用每次疊代中使用訓練集中的所有節點)。
超參數
最後,該研究對每個模型的超參數選擇採用了完全相同的策略。對學習率,隱藏層的大小,L2正則化的強度和丟失機率等都使用廣泛的網格搜索來確定。該研究限制隨機搜索空間,確保每個模型具有相同給定數量的可訓練參數。 對於每個模型,選擇在Cora和CiteSeer數據集上實現了最好平均準確度的超參數配置(平均超過100次訓練/驗證/測試分割和20次隨機初始化)。
所選擇的性能最佳的配置用於所有後續實驗,並列於表4。在所有情況下,該研究在每一類使用20個標記節點作為訓練集,30個節點作為驗證集,其餘作為測試集。
論文表4
GNN的優越性
表1顯示了所有8種模型的平均精度(及其標準差)。數據集平均超過100個分割,每個分割有20個隨機初始化。從表中可以觀察到,首先,基於GNN的方法(GCN,MoNet,GAT,GraphSAGE)在所有數據集中明顯優於所有基準算法(MLP,LogReg,LabelProp,LabelProp NL)。
這與人們的直覺相符,並證實了基於GNN的方法的優越性,結合了結構和屬性信息,而不是僅考慮屬性或僅結構的方法。
論文表1
在GNN方法中,沒有明顯的贏家在所有數據集中占主導地位。實際上,對於8個數據集中的5個,第2和第3個方法的最佳表現與平均得分相差不到1%。在該研究中,對每個數據集(已經平均了超過20個初始值)採用最佳準確度分數100%。然後,將每個模型的得分除以該數,並將每個模型的結果在所有數據集和分割上平均。另外,該研究還根據其性能對算法進行排名(1 = 最佳性能,10 =
最差性能),並計算每個算法中所有數據集和分組的平均排名。最終得分記錄在表2a中。
可以觀察到:GCN能夠在所有模型中實現最佳性能。雖然這一結果似乎令人驚訝,但其他領域也有類似的發現。如果對所有方法同樣仔細地執行超參數調整,那麼簡單的模型通常優於複雜的模型。在未來的工作中,研究者計劃進一步研究導致GNN模型性能差異的圖的特定屬性。
論文表2a
多重分割評判性能
另一個令人驚訝的發現是GAT在Amazon Computers和 Amazon Photo上得分相對較低,結果差異很大。為了研究這種現象,該研究在附錄圖2中的Amazon
Photo數據集上可視化了不同模型所獲得的準確度分數。雖然所有GNN模型的中位數彼此非常接近,但GAT將某些權重初始化為極低的分數(低於40%)。雖然這些異常值很少發生(2000次運行中有138次),但是它們顯著降低了GAT的平均得分。
論文附錄圖2
為了演示不同的訓練/驗證/測試分割對性能的影響,該研究執行以下簡單實驗。 研究者在Yang的數據集和各自的分割上運行了4個模型。如表2b所示,GAT獲得CORA和CiteSeer數據集的最佳分數,GCN獲得PubMed的最高分。
但是,如果考慮使用相同訓練/驗證/測試數據集大小的不同隨機分組,則模型的排名完全不同,GCN在CORA和CiteSeer上表現最好,而MoNet在PubMed上獲勝。這表明在單個分割中的結果非常脆弱,具有明顯的誤導性。另外考慮到GNN的預測在小數據擾動下會發生很大的變化,這一點明確證實了基於多重分割的評估策略的必要性。
論文表2b
Take home message
該研究對節點分類任務中的4種最先進的GNN架構進行了實證評估,還引入了4個新的屬性圖數據集,以及開源的框架,可以對不同的GNN模型進行公平和可重複的比較。 該研究的結果強調了:僅考慮數據的單個訓練/驗證/測試分割的實驗設置的脆弱性。 另外,該研究還驚奇地發現,如果使用相同的超參數選擇和訓練過程,簡單的GCN模型可以勝過更複雜的GNN架構,並且該結果是多個數據分割中的平均值。
希望這些結果可以鼓勵未來的工作使用更強大的評估程序。
推薦課程
2018集智俱樂部年會報名
在這樣一個特殊的Party之中,你可能邂逅正在思索深度學習與量子糾纏的「青椒」,也可能偶遇正在實踐顛覆式創新的創業者,還可能與正在尋找投資機會的金主撞個滿懷,更有機會和某個行業大咖侃侃而談。在這裡,找到與您志同道合的夥伴。
集智俱樂部QQ群|877391004
商務合作及投稿轉載|swarma@swarma.org
加入「沒有圍牆的研究所」
讓蘋果砸得更猛烈些吧!